hurlex <九> 物理内存管理的实现
这章我们来讨论操作系统内核的一个很重要的组成部分——内存管理模块。之前的章节中简单介绍了段式的内存管理,这章我们来讨论页式的内存管理。
首先是CPU在保护模式下分页未开启和分页开启的不同状态时,MMU组件处理地址的流程。
-
如果没有开启分页:
逻辑地址 -> 段机制处理 -> 线性地址 = 物理地址 -
如果开启分页:
逻辑地址 -> 段机制处理 -> 线性地址 -> 页机制处理 -> 物理地址
因为采用了平坦模式,所以给出的访问地址实际上已经等于线性地址了(段基址为0),那么剩下的问题就是所谓的页机制处理了。
长时间以来,随着计算机技术的发展,存储器的容量在不断的高速增加着。但是说起内存(这里指RAM,下同)这个东西,它有一个很奇葩的特性,就是无论它有多大,都总是不够用(P.S.厨房的垃圾桶也一样)。现在我们看似拥有着以前的程序员想都不敢想的“天文数字”的内存,动辄就是几G十几G的。但是相信我,历史总是嘲弄人的。就像当年程序员们质疑32位地址线带来的4GB空间太大没有意义似的,我们也会有一天抱怨现在的内存太小的。
那么,既然内存总是不够用的,那内存不够用了怎么办?还有,使用过程中出现的内存碎片怎么办?假设我们有4GB的物理内存,现在有1、2、3、4一共4个程序分别各占据连续的1G内存,然后2、4退出,此时虽然有空闲的两段内存,却连一个稍大于1GB的程序都无法载入了。
当然了,这只是一个例子。不过按照一般的思路,在内存释放之后,如何回收呢?做碎片整理吗?即便我们不在乎整理过程带来的效率损失,光是程序加载时候的地址逐一重定位就是及其麻烦的。那怎么办?当然了,解决的办法是有的,聪明的计算机工程师们想到了采用分页的方式来管理物理内存。他们在逻辑上把内存划分为定长的物理页,同时将一个程序执行时候的线性地址地址空间划分为逻辑页,在分页机制工作的前提下,给硬件提供一组数据结构来保存这种映射关系。也就是说,线性地址是连续的,但是其实际指向的物理地址就不见得是连续的了。别忘了,RAM是随机存储器,读取任意一个地址的理论时间都是一样的(暂时让我们忘了cache吧)。我们让CPU在寻址的时候,自动去查找线性地址到物理地址的映射关系,从而找到实际的数据就好。严格说地址翻译是由MMU组件来进行的,但是现在MMU一般都是CPU的一个组成部分了,所以也就不严格区分了。
下面的图片描述了这个映射关系:
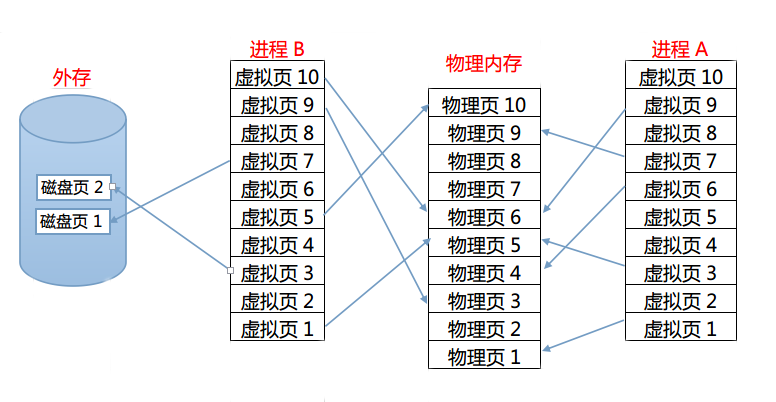
一图胜千言,我们看到了固定大小的物理页、虚拟页、甚至还有磁盘页。我觉得这张图片很能说明问题了,相信聪明的你从这里都悟出来了虚拟内存的实现原理了。没错,虚拟内存实质上就是把物理内存中暂时用不到的内容暂时换出到外存里,空出内存放置现阶段需要的数据。至于替换的策略当然有相应的算法了,比如最先换入原则,最少使用原则等等方法可以使用。
相信通过上文的描述,我们对分页已经建立了初步的理解了。那么接下来的问题是,怎么表示和存储这个映射关系。这里描述起来简单,但是代码就不是那么直观了,原因很简单,因为需要一组数据结构来管理内存,但是这组数据结构本身也得放在内存里。所以牵扯到一个自己管理自己的问题。而且,开启分页模式之后,CPU立即就会按照分页模式的规则去解释线性地址了。所以,这意味着必须先建立好地址映射的数据结构,才能开启分页,而且必须保证之前的代码地址和数据地址都能映射正确。
下面我们来说说x86下的一种简单的做法吧。
在32位操作系统下使用32位地址总线(暂时原谅我在这里错误的描述吧,其实还有PAE这个东西),所以寻址空间有2的32次方,也就是4GB。一定要注意,我们强调了很多次了,这个空间里,有一些断断续续的地址实际上是指向了其它的外设,不过大部分还是指向RAM的。具体采取的分页大小可以有多种选择,但是过于小的分页会造成管理结构太大,过于大的分页又浪费内存。现在较为常见的分页是4KB一个页,也就是4096字节一个页。简单计算下,4GB的内存分成4KB一个的页,那就是1MB个页,没错吧?每个虚拟页到物理页的映射需要4个字节来存储的话(别忘了前提是32位环境下),整个4GB空间的映射需要4MB的数据结构来存储。
目前看起来一切都很好,4MB似乎也不是很大。但是,这只是一个虚拟地址空间的映射啊,别忘了每个进程都有自己的映射,而且操作系统中通常有N个进程在运行。这样的话,假如有100个进程在运行,就需要400MB的内存来存储管理信息!这就太浪费了。
怎么办?聪明的工程师们提出了分级页表的实现策略,他们提出了页目录,页表的概念。以32位的地址来说,分为3段来寻址,分别是地址的低12位,中间10位和高10位。高10位表示当前地址项在页目录中的偏移,最终偏移处指向对应的页表,中间10位是当前地址在该页表中的偏移,我们按照这个偏移就能查出来最终指向的物理页了,最低的12位表示当前地址在该物理页中的偏移。就这样,我们就实现了分级页表。
我们来张图看看:
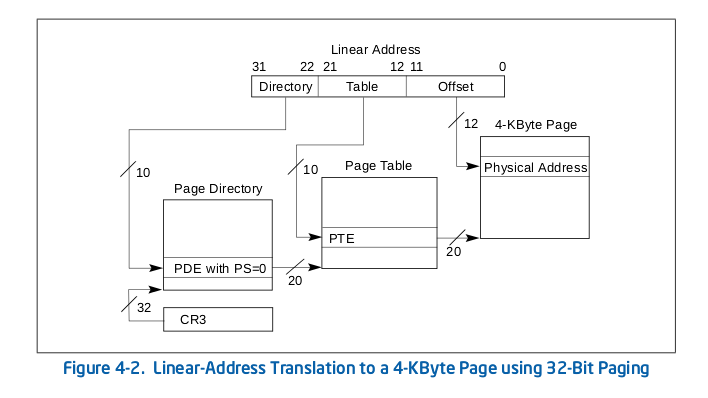
也许你已经算出来了,这样做的话映射4GB地址空间需要4MB+4KB的内存。我们这是搬起石头砸了自己的脚吗?当然不是,因为在一个进程中,实际使用到的内存大都远没有4GB这么大,所以通过两级页表的映射,我们就可以只映射需要的地址就可以了,是不是节省了内存呢?概念我们暂时就说到这里,更专业的描述和规范请参阅Intel文档,也就是上面那张图片的出处。
说完了理论,接下来就是具体的实现了。我们把内存管理分为物理内存管理和虚拟内存管理两个部分来进行。本章讨论物理内存的管理。要实现内存的管理,首先要解决以下三个问题:
-
如何获取可用物理内存的大小和地址?
-
采用什么样的数据结构来描述物理内存?
-
申请和释放物理内存的算法如何实现?
我们先来解决第一个问题。获取物理内存的方法一般有BIOS调用和直接探测等方法,但是GRUB的Mutliboot协议提供了更简单的方法。还记得那个multiboot_t结构体吗?GRUB已经获取了物理内存的分布并且把它们放置在了这个结构体里的以下两个成员里。
typedef
struct multiboot_t {
... ...
/**
* 以下两项指出保存由 BIOS 提供的内存分布的缓冲区的地址和长度
* mmap_addr 是缓冲区的地址, mmap_length 是缓冲区的总大小
* 缓冲区由一个或者多个下面的 mmap_entry_t 组成
*/
uint32_t mmap_length;
uint32_t mmap_addr;
... ...
} __attribute__((packed)) multiboot_t;
/**
* size 是相关结构的大小,单位是字节,它可能大于最小值 20
* base_addr_low 是启动地址的低32位,base_addr_high 是高 32 位,启动地址总共有 64 位
* length_low 是内存区域大小的低32位,length_high 是内存区域大小的高 32 位,总共是 64 位
* type 是相应地址区间的类型,1 代表可用 RAM,所有其它的值代表保留区域
*/
typedef
struct mmap_entry_t {
uint32_t size; // size 是不含 size 自身变量的大小
uint32_t base_addr_low;
uint32_t base_addr_high;
uint32_t length_low;
uint32_t length_high;
uint32_t type;
} __attribute__((packed)) mmap_entry_t;
GRUB将内存探测的结果按每个分段整理为mmap_entry结构体的数组。mmap_addr是这个结构体数组的首地址,mmap_length是整个数组的长度。
这里需要留意的是mmap_entry结构体的size成员指的是除了size之外的成员的大小。至于base和length拆为了两段是因为物理地址可能用32位表示不下,不过我们只考虑32位操作系统,而且暂时只支持512MB的内存即可。type成员用来描述这个内存段的属性,因为物理不一定指向RAM里,也可能是其它外设。
下面的代码实现了遍历这个结构,打印所有物理内存段的操作:
#include "multiboot.h"
#include "common.h"
#include "debug.h"
#include "pmm.h"
void show_memory_map()
{
uint32_t mmap_addr = glb_mboot_ptr->mmap_addr;
uint32_t mmap_length = glb_mboot_ptr->mmap_length;
printk("Memory map:\n");
mmap_entry_t *mmap = (mmap_entry_t *)mmap_addr;
for (mmap = (mmap_entry_t *)mmap_addr; (uint32_t)mmap < mmap_addr + mmap_length; mmap++) {
printk("base_addr = 0x%X%08X, length = 0x%X%08X, type = 0x%X\n",
(uint32_t)mmap->base_addr_high, (uint32_t)mmap->base_addr_low,
(uint32_t)mmap->length_high, (uint32_t)mmap->length_low,
(uint32_t)mmap->type);
}
}
现在第一个问题解决了。等等,我们还需要知道内核本身加载到物理内存的位置信息,这块内存必须是物理内存管理所保留的。那怎么获取呢?看起来很困难,其实解决起来特别容易。大家想想,链接器负责了整个内核文件的链接和重定位工作,肯定知道内核文件加载到内存中的位置。我们修改链接器脚本,定义两个变量:
... ...
. = 0x100000;
PROVIDE( kern_start = . );
.text :
{
*(.text)
. = ALIGN(4096);
}
... ....
.stabstr :
{
*(.stabstr)
. = ALIGN(4096);
}
PROVIDE( kern_end = . );
... ...
从上面的代码里可以看到最先放置的段.text的开始位置和最后一个段.stabstr的结尾分别定义了两个变量kern_start和kern_end,这两个变量在C代码里声明后就可以使用了。
我们添加如下的头文件:
#ifndef INCLUDE_PMM_H
#define INCLUDE_PMM_H
#include "multiboot.h"
// 内核文件在内存中的起始和结束位置
// 在链接器脚本中要求链接器定义
extern uint8_t kern_start[];
extern uint8_t kern_end[];
// 输出 BIOS 提供的物理内存布局
void show_memory_map();
#endif // INCLUDE_PMM_H
接着修改入口函数进行测试,代码如下:
#include "console.h"
#include "debug.h"
#include "gdt.h"
#include "idt.h"
#include "timer.h"
#include "pmm.h"
int kern_entry()
{
init_debug();
init_gdt();
init_idt();
console_clear();
printk_color(rc_black, rc_green, "Hello, OS kernel!\n\n");
init_timer(200);
// 开启中断
// asm volatile ("sti");
printk("kernel in memory start: 0x%08X\n", kern_start);
printk("kernel in memory end: 0x%08X\n", kern_end);
printk("kernel in memory used: %d KB\n\n", (kern_end - kern_start + 1023) / 1024);
show_memory_map();
return 0;
}
编译运行之后结果如下:
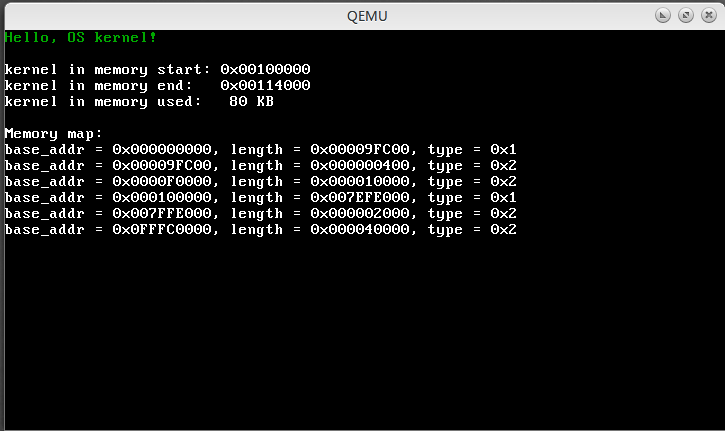
我们采用的是qemu虚拟机默认的配置,所以物理内存大约是32MB。从这个输出结果中可以看到,可用的内存段是1MB以下的0x0-0x9FC00和1M以上的0x100000-0x7EFE000两段。需要注意的是这个区域随着我们的虚拟机内存设置不同而不同,所以这个值只是我自己虚拟机跑出来的一种结果。另外我们也成功的输出了内核的起始位置0x100000(1MB处)和结束位置0x114000以及占用的内存大小是80KB。1
第一个问题算是完全解决了,下面是第二个问题:采用什么样的数据结构来描述物理内存?
为了支持后续的虚拟内存管理,物理内存也必须按照4KB的页框来管理内存。21MB以下的物理地址区域有太多的外设的存储区域映射在这里,为了大家实验的时候避免一些不必要的麻烦,我们不使用1MB以下的零碎物理内存,而是直接在1MB以上支持最多512MB的物理内存管理。
物理内存管理算法最著名的就是Linux内核所采用的伙伴算法了,这方面的资料也很容易获取到。伙伴算法在申请和释放物理页框的时候会对物理页框进行合并操作,尽可能的保证可用物理内存的连续性。这里需要引入内存碎片这个概念,内存碎片分为内部碎片和外部碎片两种。内部碎片就是已经被分配出去却不能被利用的内存空间,比如我们为了管理方便,按照4KB内存块进行管理。此时任何申请内存的操作都会以4KB的倍数返回内存块。即使申请1个字节也返回指向4KB大的内存块的指针,这样的话造成了分配出去的内存没有被有效利用,而且剩余空间无法分配给其它进程(因为最小的管理单位是4KB)。外部碎片是指内存频繁请求和释放大小不同的连续页框后,导致在已分配页框块周围分散了许多小块空闲的页框,尽管这些空闲页框的总数可以满足接下来的请求,但却无法满足一个大块的连续页框。
不过在本章并不会去实现伙伴算法。理由很简单,如果在大家对物理内存管理都没有概念的时候就贸然引入伙伴算法后带来的机制和策略的双重复杂性就难以学习和接受了。我们会采用一个很简单的策略来对内存进行管理操作:将物理页面的管理地址设定在1MB以上内核加载的结束位置之后,从这个起始位置到512MB的地址处将所有的物理内存按页划分,将每页的地址放入栈里存储。这样在需要的时候就可以按页获取到物理内存了,具体的实现如下:
#include "multiboot.h"
#include "common.h"
#include "debug.h"
#include "pmm.h"
// 物理内存页面管理的栈
static uint32_t pmm_stack[PAGE_MAX_SIZE+1];
// 物理内存管理的栈指针
static uint32_t pmm_stack_top;
// 物理内存页的数量
uint32_t phy_page_count;
void show_memory_map()
{
uint32_t mmap_addr = glb_mboot_ptr->mmap_addr;
uint32_t mmap_length = glb_mboot_ptr->mmap_length;
printk("Memory map:\n");
mmap_entry_t *mmap = (mmap_entry_t *)mmap_addr;
for (mmap = (mmap_entry_t *)mmap_addr; (uint32_t)mmap < mmap_addr + mmap_length; mmap++) {
printk("base_addr = 0x%X%08X, length = 0x%X%08X, type = 0x%X\n",
(uint32_t)mmap->base_addr_high, (uint32_t)mmap->base_addr_low,
(uint32_t)mmap->length_high, (uint32_t)mmap->length_low,
(uint32_t)mmap->type);
}
}
void init_pmm()
{
mmap_entry_t *mmap_start_addr = (mmap_entry_t *)glb_mboot_ptr->mmap_addr;
mmap_entry_t *mmap_end_addr = (mmap_entry_t *)glb_mboot_ptr->mmap_addr + glb_mboot_ptr->mmap_length;
mmap_entry_t *map_entry;
for (map_entry = mmap_start_addr; map_entry < mmap_end_addr; map_entry++) {
// 如果是可用内存 ( 按照协议,1 表示可用内存,其它数字指保留区域 )
if (map_entry->type == 1 && map_entry->base_addr_low == 0x100000) {
// 把内核结束位置到结束位置的内存段,按页存储到页管理栈里
// 最多支持512MB的物理内存
uint32_t page_addr = map_entry->base_addr_low + (uint32_t)(kern_end - kern_start);
uint32_t length = map_entry->base_addr_low + map_entry->length_low;
while (page_addr < length && page_addr <= PMM_MAX_SIZE) {
pmm_free_page(page_addr);
page_addr += PMM_PAGE_SIZE;
phy_page_count++;
}
}
}
}
uint32_t pmm_alloc_page()
{
assert(pmm_stack_top != 0, "out of memory");
uint32_t page = pmm_stack[pmm_stack_top--];
return page;
}
void pmm_free_page(uint32_t p)
{
assert(pmm_stack_top != PAGE_MAX_SIZE, "out of pmm_stack stack");
pmm_stack[++pmm_stack_top] = p;
}
其对应的头文件如下:
#ifndef INCLUDE_PMM_H
#define INCLUDE_PMM_H
#include "multiboot.h"
// 线程栈的大小
#define STACK_SIZE 8192
// 支持的最大物理内存(512MB)
#define PMM_MAX_SIZE 0x20000000
// 物理内存页框大小
#define PMM_PAGE_SIZE 0x1000
// 最多支持的物理页面个数
#define PAGE_MAX_SIZE (PMM_MAX_SIZE/PMM_PAGE_SIZE)
// 页掩码 按照 4096 对齐地址
#define PHY_PAGE_MASK 0xFFFFF000
// 内核文件在内存中的起始和结束位置
// 在链接器脚本中要求链接器定义
extern uint8_t kern_start[];
extern uint8_t kern_end[];
// 动态分配物理内存页的总数
extern uint32_t phy_page_count;
// 输出 BIOS 提供的物理内存布局
void show_memory_map();
// 初始化物理内存管理
void init_pmm();
// 返回一个内存页的物理地址
uint32_t pmm_alloc_page();
// 释放申请的内存
void pmm_free_page(uint32_t p);
#endif // INCLUDE_PMM_H
最后修改入口函数为以下内容:
#include "console.h"
#include "debug.h"
#include "gdt.h"
#include "idt.h"
#include "timer.h"
#include "pmm.h"
int kern_entry()
{
init_debug();
init_gdt();
init_idt();
console_clear();
printk_color(rc_black, rc_green, "Hello, OS kernel!\n");
init_timer(200);
// 开启中断
// asm volatile ("sti");
printk("kernel in memory start: 0x%08X\n", kern_start);
printk("kernel in memory end: 0x%08X\n", kern_end);
printk("kernel in memory used: %d KB\n\n", (kern_end - kern_start) / 1024);
show_memory_map();
init_pmm();
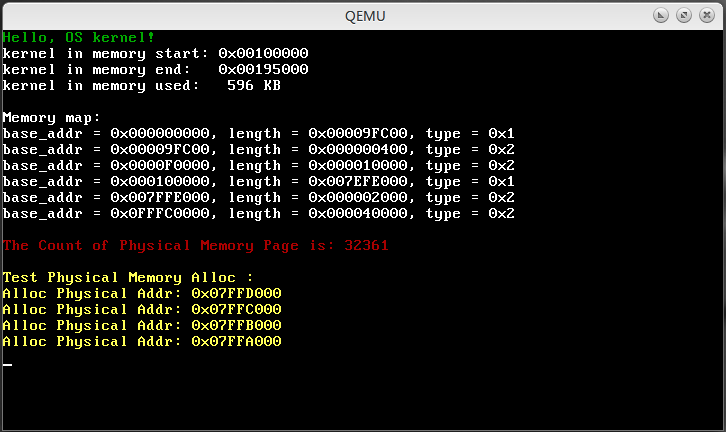
printk_color(rc_black, rc_red, "\nThe Count of Physical Memory Page is: %u\n\n", phy_page_count);
uint32_t allc_addr = NULL;
printk_color(rc_black, rc_light_brown, "Test Physical Memory Alloc :\n");
allc_addr = pmm_alloc_page();
printk_color(rc_black, rc_light_brown, "Alloc Physical Addr: 0x%08X\n", allc_addr);
allc_addr = pmm_alloc_page();
printk_color(rc_black, rc_light_brown, "Alloc Physical Addr: 0x%08X\n", allc_addr);
allc_addr = pmm_alloc_page();
printk_color(rc_black, rc_light_brown, "Alloc Physical Addr: 0x%08X\n", allc_addr);
allc_addr = pmm_alloc_page();
printk_color(rc_black, rc_light_brown, "Alloc Physical Addr: 0x%08X\n", allc_addr);
return 0;
}
最终的测试结果如图所示: